The CLARIAH CORE infrastructure was developed in four separate work packages: generic infrastructure (WP2), language technology (WP3), semantic structured data technology (WP4), and audio-video technology (WP5). Except for WP2 these packages served largely separate research communities and ran on separate platforms.
Context
CLARIAH CORE's most important - albeit intangible - success was the establishment of trust among the different partners in the various work packages. It took until the end of the project to achieve some success in bringing the different strands of technology together. This cooperation was taken as the basis for the CLARIAH PLUS proposal. During several brainstorm sessions the CLARIAH tech community defined a number of topics crucial for the entire field. The community deemed the actual development of software for these topics to go beyond the needs of single research community, and thus no longer belonged in work packages 3, 4 and 5 - but in WP2. The original topics were:
- (Web)annotations
- Geo technology
- Image technology
- Speech technology
- Text technology
- Recommender systems technology
- Triplestore/Graph database technology
- Components for graphical user interfaces
- Security, authentication, authorization and logging
- VRE/workflow management, pipelines and recipes
- Data standards, vocabularies & ontologies
Infrastructure classification
The list appeared to be a selection of interests that required more fundamental classification. This classification was the topic of discussions in the first quarter of 2019. I was joined in these discussions by Antal van den Bosch, Ronald Dekker, Marieke van Erp, Jauco Noordzij, Marijn Koolen and Arno Bosse. We found Unsworth’s scholarly primitives to be an applicable guide to classifying the components. The list above was reduced to four classes:
(1) Models such as geo/image/speech/text data standards, vocabularies and ontologies;
(2) Prerequisites such as security, authentication, authorization, logging, etc.;
(3) Transformations such as VRE, workflow management, pipelines, recipes, etc.; and
(4) Interactions, which focus not only on visualisations and graphical user interfaces, but also on non-GUI interactions.
This classification (interactions, transformations, models, and prerequisites) can be layered from specific to generic. Interactions are closest to the user and often require custom solutions to answer specific research questions within an academic (sub-)discipline. Transformations, such as NLP pipelines and recipe workflows, are more generic and applicable to multiple use cases across SSH disciplines, while Models transcend the boundaries of academic fields. Prerequisites are even more universal and can no longer be considered part of the academic domain.
Sidebar: We found that this classification also effectively addressed the earlier “80-20 discussion” in CLARIAH CORE, which works from the assumption that 80% of humanities scholars want to interact with an infrastructure through GUI-based tools, and 20% through APIs writing code. It is a fact that more and more researchers desire a direct interaction with infrastructure through code, ranging from R or custom Python scripts to more guided solutions like Jupyter Notebooks. Although they may not have reached the illustrious status of 20% - adoption is certainly increasing rapidly and code-based interaction should be a core feature of any infrastructure.
CLARIAH-as-a-Service
Our discussions led to a first draft of the CLARIAH-as-a-Service (CLaaS) plan that I presented to the CLARIAH Board in Spring 2019. The design was developed further in the second quarter of 2019 and presented to a range of (international) partners as well as the Dutch Network for Digital Heritage (NDE). This led to the addition of a new class: DevOps, which is a collection of services and components required by engineers to develop, test and deploy software on top of the infrastructure. The DevOps class is inherently more universal than Prerequisites as it is generic enough to develop any of the other services.
The scale from specific-to-generic naturally led to the conclusion that the five component classes all rest on an ultimate generic class of infrastructure services: those that serve computational resources. Think about storage, processing power, memory, and network connections: these apply equally to cars, washing machines, doorbells, space stations, as much as they do to analytical software for research questions in highly specialised academic sub-disciplines.
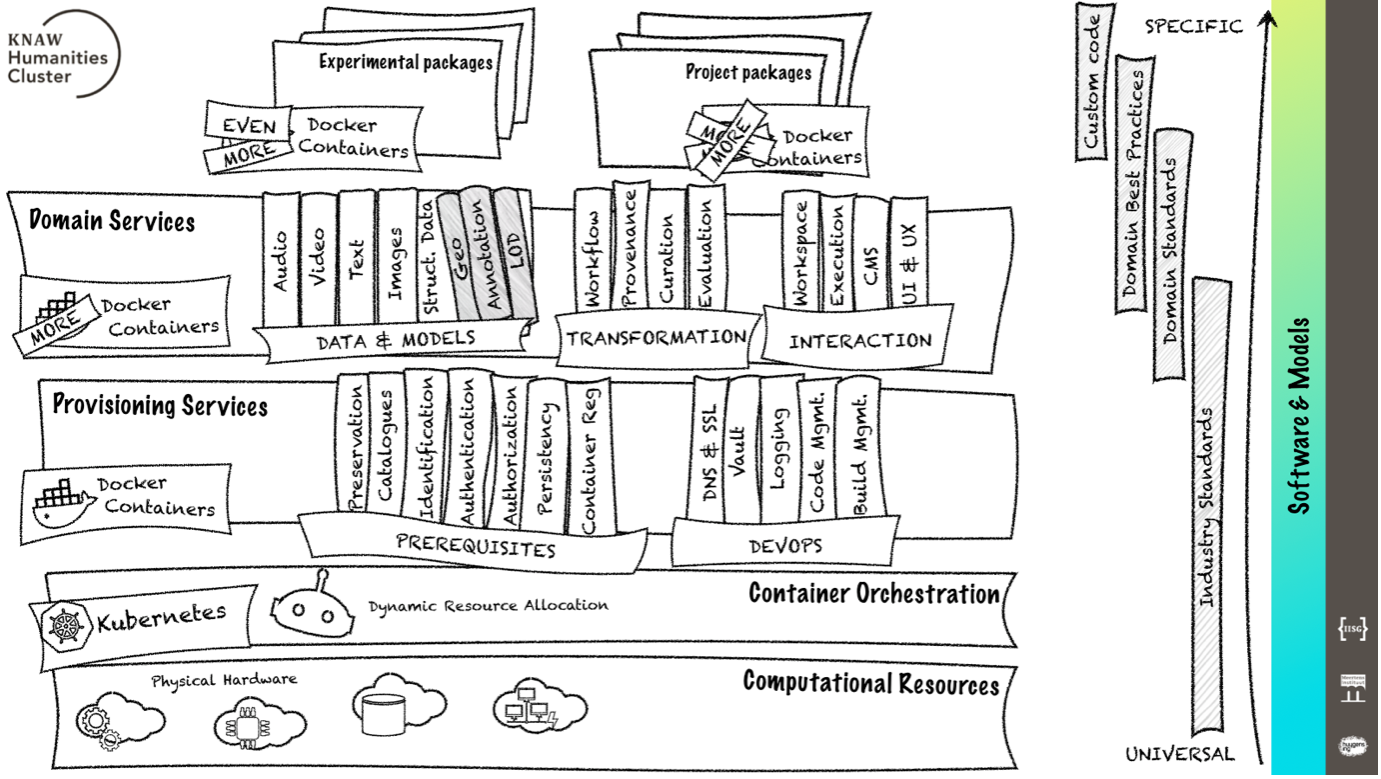
The architectural model behind CLaaS consists of layers in which the component classes described earlier, are grouped together. The lowest layer contains the Computational Resources hosted by institutions. The Container Orchestration layer dynamically distributes these resources to software services. This layer allows for the fluid upscaling and downscaling of resource allocation, meaning that resources – such as processor capacity and memory – of dormant service containers can be used by active services. This makes the infrastructure not only more cost effective but also more reliable and performant, and, as a result, more sustainable.
The actual CLARIAH software is divided over two layers. A layer for Provisioning Services which contains components classified as Prerequisites and Devops. A further layer contains Domain Services and consists of the Models, Transformations, and Interactions classes. Finally, in accordance with the scale of specific-to-generic, a final layer contains both experiments and tools developed by scientific programmers in other projects like NWO Open Competition, NWO Groot, NWA, etc. All these projects can make use of the CLARIAH infrastructure. This layer serves the both digitally oriented researchers and more traditional scholars. And although the layer is outside the scope of generic infrastructure it is likely to contain software components developed in the CLARIAH work packages that focus on specific research communities.
CLaaS Reference Implementations
Conducive to interoperability, all components in the architecture are primarily considered to be sets of conceptual agreements. A commonly accepted definition within the CLARIAH community on what e.g. we mean when we talk about a ‘workflow engine’ is fundamental before the actual development of software implementing such an engine starts.
We decided to formulate these definitions as one or more sets of APIs and data models, allowing anyone to adopt the infrastructure without being forced to run a specific software implementation.
Over the course of the CLARIAH PLUS project each of the components in the CLaaS architecture is intended to be both precisely defined as a set of APIs and implemented in at least one running software component. The CLaaS Reference Implementation is the full set of all these components.
In many instances definitions already exist. For the lower layers of the architecture the necessity to come to a commonly accepted new definition is small. There is clearly no need to draw up a different concept of e.g. a processor or memory bank in CLARIAH.
By principle: the more specific a layer of infrastructure becomes, the more thorough the analysis of the concepts will have to be, the larger the effort required, and the likelier CLARIAH will have to be involved.
Since the greatest effort in terms of resources and time is the development of unique software, the development of CLARIAH-specific implementations in any layer below Domain Services, is considered to be controversial. This principle forces the community to focus its development efforts. Although CLARIAH would never consider defining and building a new processor, there have been discussions on whether or not to develop software for other more generic layers. Whenever unique feature requests for services like security, preservation, cataloguing, etc. come up, the CLARIAH community should challenge these requests instead of automatically building and maintaining a new and uniquely specific code base.